The Importance of Red Teaming for AI and Machine Learning Models
M
I am a software architect with over a decade of experience in architecting and building software solutions.
Search for a command to run...
No comments yet. Be the first to comment.
In this series, I will be explaining AI in a structured, step-by-step manner, helping readers "decode" complex topics.
Adversarial testing is a method of testing systems—especially AI models, software, or security mechanisms—by intentionally trying to break them, fool them, or find their weaknesses using carefully cra
Gateway, API gateway, AI-native gateway: the concept ladder, the real players, and where AgentGateway actually stands next to AWS, Azure, Kong, and LiteLLM.

The biggest LLM-consumption release yet: a purpose-built UI, per-token cost attribution, and virtual models that reroute traffic without touching a single client.

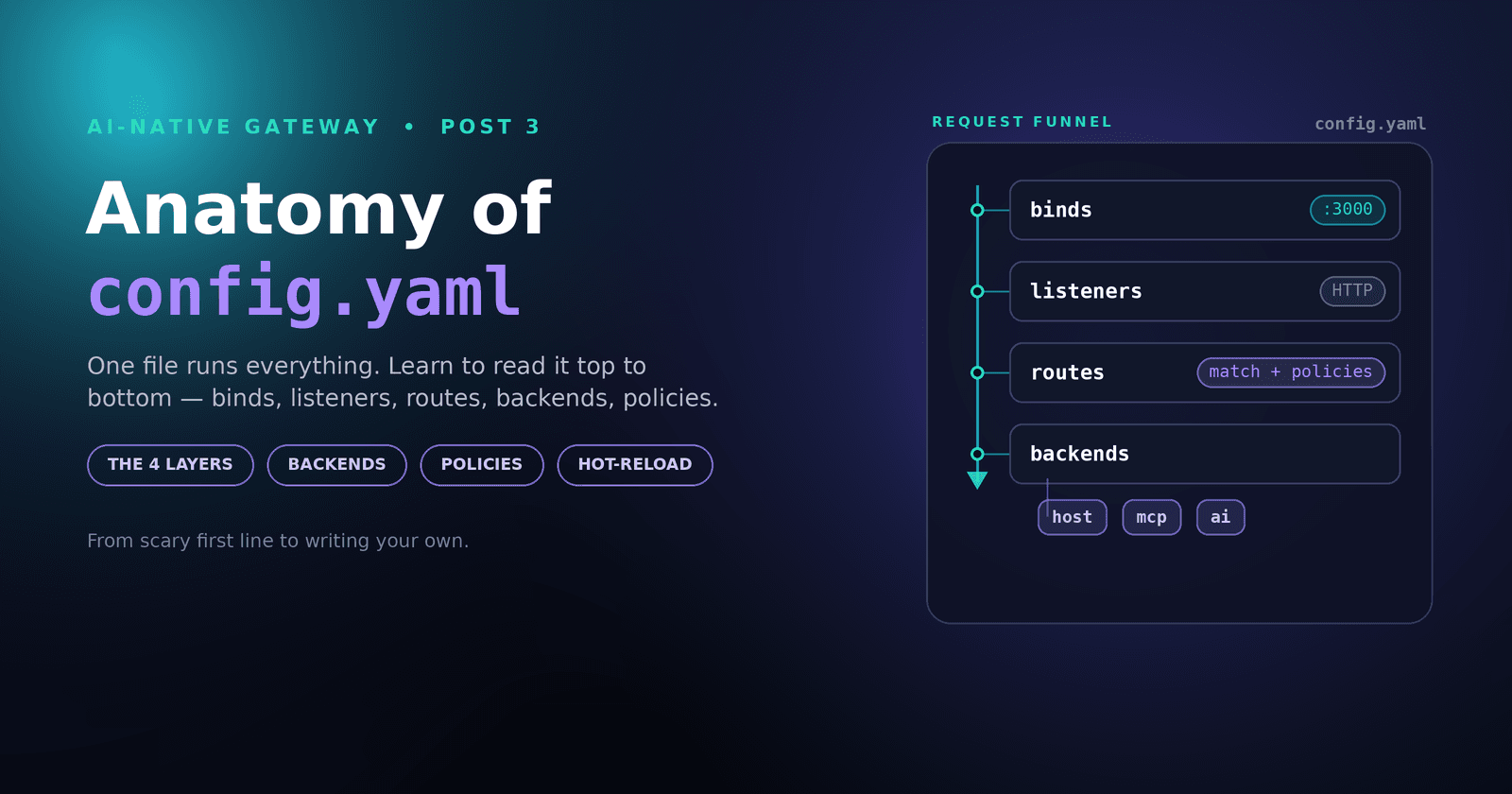
One file runs everything — binds, listeners, routes, backends, policies. Here's how to read it top to bottom, and why the same skeleton powers an MCP gateway, an LLM gateway, and a plain proxy.
No Rust, no Docker, no compiling. Grab the Windows binary, write a tiny config, and watch a real MCP tool server show up in your browser.

One open-source proxy for LLMs, MCP tools, agents, and your regular APIs, plus the data-plane and control-plane vocabulary you'll keep running into.

AI models are getting better every day—but there are people try to break them. And if you’ve ever deployed a model into the wild, you probably already know: what works in the lab doesn’t always hold up under real-world pressure.
👉That’s where red teaming comes in.
Originating from cybersecurity and military strategy, red teaming involves a designated group of testers ("red team") who think like adversaries, attempting to "break" or manipulate a system to test its defenses and resilience.
Think of it this way: if your model is a fortress, the red team’s job is to act like an intruder. Their goal isn’t to follow the rules—it’s to find the cracks, the loopholes, the vulnerabilities.
In practice, red teaming means trying to trick, mislead, or misuse an AI model to see how it reacts. That includes:
Writing prompts that push ethical boundaries
Testing whether the model can be manipulated with sneaky language
Probing for bias, hallucinations, or unsafe outputs
Simulating “bad actor” behavior (without being one)
Unlike regular QA, which checks if the model works, red teaming asks:
“How can it fail?”

Because as AI systems become more powerful—and more integrated into daily life—the cost of failure goes up. An embarrassing chatbot mistake might be a PR issue. But an unsafe model in healthcare, law, or finance? That’s a serious risk.
Red teaming helps you spot problems before your users (or bad actors) do.
In other words, it’s proactive—not reactive. It’s how you build trust into the product from day one.
You don’t need a secret bunker or a black-ops team to start red teaming. In most cases, it looks like this:
Start with realistic threat scenarios
Craft adversarial prompts
Analyze responses in context
Feed the findings back into your dev cycle
And yes, this process can be uncomfortable. You’ll discover weaknesses. That’s the point.
Before releasing GPT-4, OpenAI brought in external red teamers to probe the model’s limits. They tested for misinformation, jailbreaks, bias—you name it.
Their feedback helped shape the safety layers that shipped with the final product. It’s a textbook example of red teaming done right: practical, human-focused, and high-impact.
Let’s clear this up—these aren’t competing approaches. They’re complementary.
| Testing Type | Focus | Input Style | Mindset |
| QA/Validation | Does the model behave as expected? | Clean, structured | Confirm what works |
| Red Teaming | How can the model be misused or fail? | Adversarial, deceptive | Find what breaks |
There’s no “perfect” time—but there are a few smart ones:
Before major model releases
When fine-tuning on sensitive topics
As part of safety evaluations or audits
Anytime you’re deploying in the wild
Early is good. Ongoing is better.
Red teaming is one of those practices that might feel like a “nice-to-have” until the first time it catches something big. Then it becomes a must-have.
It's not just about security. It’s about responsibility.
As people building the future of AI, we owe it to our users—and ourselves—to ask the hard questions up front. Red teaming is how we do that.