From Text Generation to Reasoning in AI
M
I am a software architect with over a decade of experience in architecting and building software solutions.
Search for a command to run...
No comments yet. Be the first to comment.
In this series, I will be explaining AI in a structured, step-by-step manner, helping readers "decode" complex topics.
Introduction Although AI agent systems are often presented as something entirely new, many of their architectural patterns will feel familiar to anyone who has worked with microservices. In practice,
Gateway, API gateway, AI-native gateway: the concept ladder, the real players, and where AgentGateway actually stands next to AWS, Azure, Kong, and LiteLLM.

The biggest LLM-consumption release yet: a purpose-built UI, per-token cost attribution, and virtual models that reroute traffic without touching a single client.

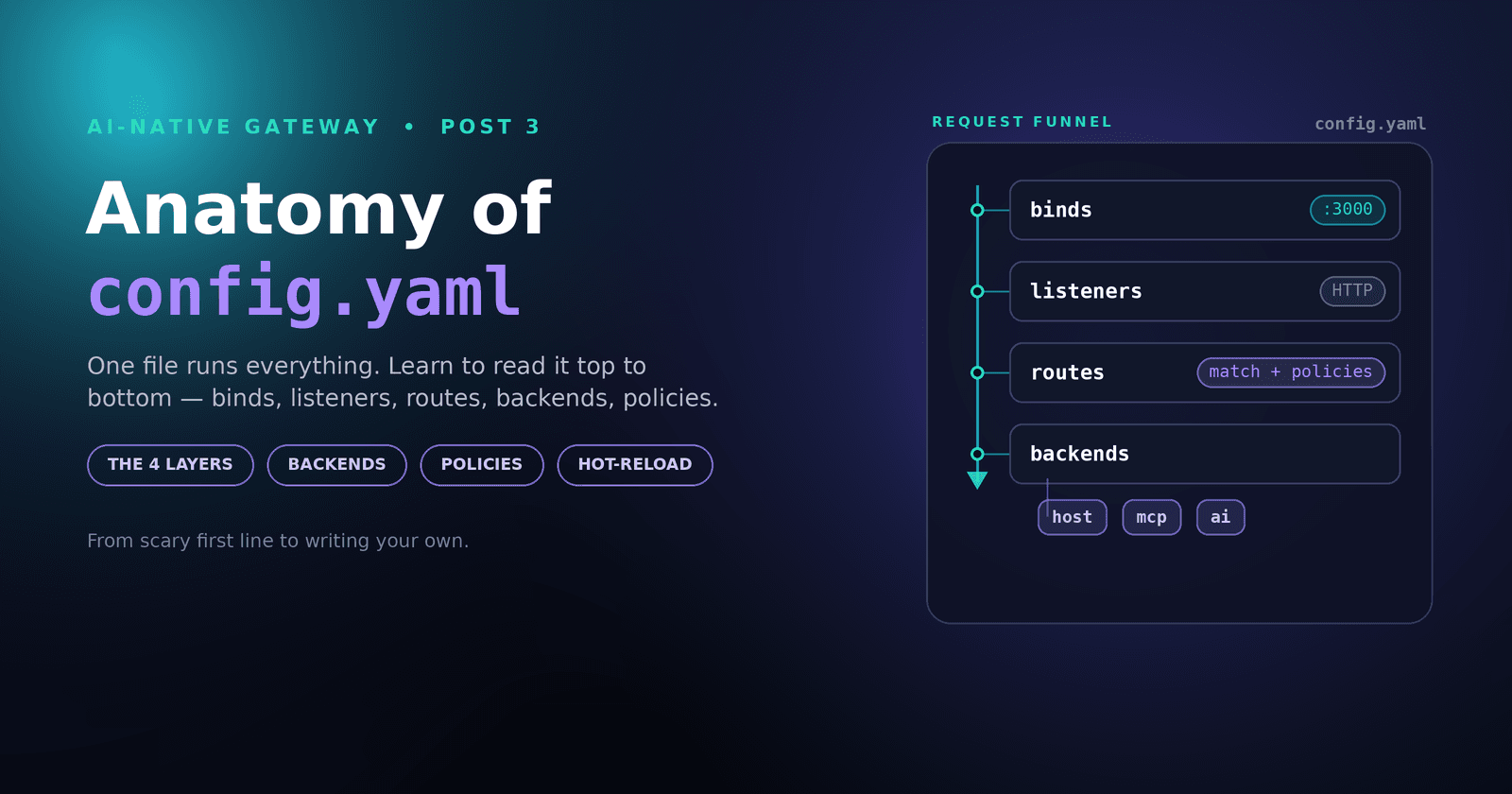
One file runs everything — binds, listeners, routes, backends, policies. Here's how to read it top to bottom, and why the same skeleton powers an MCP gateway, an LLM gateway, and a plain proxy.
No Rust, no Docker, no compiling. Grab the Windows binary, write a tiny config, and watch a real MCP tool server show up in your browser.

One open-source proxy for LLMs, MCP tools, agents, and your regular APIs, plus the data-plane and control-plane vocabulary you'll keep running into.

Large Language Models (LLMs) such as ChatGPT, Claude and Gemini have moved quickly from research labs into everyday use. They write emails, summarize documents, and hold conversations well enough that many people treat them as if they “understand” what they’re saying.
But something important is changing beneath the surface.
As impressive as LLMs are, their strengths also reveal a limitation: fluency is not the same as reasoning. That gap is what has driven the emergence of Large Reasoning Models (LRMs)—systems designed not just to respond convincingly, but to work through problems deliberately and correctly.
A Large Language Model is a powerful AI trained on essentially the entire internet. Its genius lies in statistical pattern recognition. When you give it a prompt, it predicts the next most likely word (or "token"), then the next, chaining them into coherent, human-like text.
Think of it as an incredibly sophisticated autocomplete. It doesn't "understand" in a human sense; it identifies patterns from its training data.
This makes LLMs exceptional for:
Drafting emails and blog posts
Creative storytelling and brainstorming
Summarizing long documents
General conversation and Q&A on familiar topics

A Large Reasoning Model is what you get when you build deliberate, structured thought on top of an LLM's foundation. If an LLM provides a quick reflex, an LRM offers a considered reflection.
The key difference is the internal "chain of thought." Before generating an answer, an LRM pauses to:
Plan: Sketch a roadmap to a solution.
Execute: Work through multi-step calculations or logic.
Verify: Double-check steps in an internal "sandbox" before committing to a final answer.
This allows LRMs to tackle problems where the statistically likely next word is often the wrong one—like debugging complex code, tracing a financial discrepancy, or solving a logic puzzle.

Creating an LRM isn't about building a new model from scratch, but about teaching an existing LLM to reason. The process is intensive and layered:
Start with a Strong LLM Foundation: It begins with a heavily pre-trained LLM, which already possesses vast world knowledge and language mastery.
Reasoning-Focused Fine-Tuning: This is the crucial step. The model is trained on specialized datasets—collections of math word problems, logic puzzles, and code challenges—where each example includes a full, step-by-step solution. The model learns to emulate this "show your work" process.
Reinforcement Learning from Process Feedback: Here, the model's reasoning steps are judged, not just its final answer. A Process Reward Model (PRM) evaluates each interim step for quality. Through reinforcement learning, the LRM learns to generate reasoning chains that are logically sound, maximizing its "reward."
Knowledge Distillation: Often, a larger, more capable "teacher" model generates high-quality reasoning traces. These are then used to train a more efficient "student" model, effectively transferring reasoning skills.
The outcome is a system trained to pause, plan, and verify, making it robust for complex, multi-domain problems.

LRMs and LLMs are family, sharing a core DNA:
Architecture: Both are built on transformer-based neural networks.
Training Foundation: Both undergo initial pre-training on colossal text and code datasets.
Core Output: Both ultimately communicate through natural language.
| Aspect | Large Language Model (LLM) | Large Reasoning Model (LRM) |
|---|---|---|
| Primary Mechanism | Next-token prediction (statistical pattern-matching). | Multi-step planning and logical deliberation / thinking. |
| Response Generation | Immediate, fluent generation. | Plan -> Execute Steps -> Verify -> Respond. |
| Optimal Use Case | Tasks requiring fluency, creativity, and speed: content creation, summarization, casual dialogue. | Tasks requiring logic, planning, and accuracy: complex code debugging, financial analysis, strategic planning. |
| Compute & Cost | Lower inference cost and latency (faster, cheaper per query). | Higher inference cost and latency (more "thinking" passes = more compute and time). |
| Prompt Reliance | Often requires clever prompting (e.g., "Let's think step by step") to elicit reasoning. | Has structured reasoning baked into its core process. |
| Analogy | A brilliant, quick-witted conversationalist. | A meticulous scientist who shows all their calculations. |
The rise of LRMs marks a shift from AI that speaks to AI that reasons. Today's top-performing models on advanced benchmarks are increasingly reasoning models.
When to use an LLM: For tasks where speed, creativity, and low cost are paramount—social media posts, brainstorming, or simple queries—an LLM's reflex is perfectly sufficient.
When an LRM is worth the cost: For problems where accuracy, logical soundness, and multi-step deduction are critical—untangling complex code, analyzing financial structures, or solving intricate planning problems—the LRM's deliberate think-time is a worthy investment.
The future of AI isn't just about faster text generation; it's about building systems that pause, reason, and show their work. LRMs represent a significant step toward that future, offering not just answers, but accountable and verifiable thought processes.